Person With Ball ⛹
(this is an edited version of a text which first appeared in Sign of the Times: Understanding Insignia in a World of Flux, connected to the exhibition Sign of the Times, at the Zeeuws Museum)
{kind=link}
Emoji are familiar to everyone who has used an instant-messaging application. These colourful pictograms are one of the most remarkable features of communications in recent years. They are used in almost every online conversation to give statements extra emphasis or to suggest irony, humour or flirtation. Since their introduction in 2010, they have quickly become mainstream and are used by young and old alike. They are even used in corporate communications, often in a somewhat awkward attempt to make PR a little more contemporary. You could say that they are merely a banal curiosity, but a closer look reveals them to be a phenomenon on the cutting edge of two of the most urgent political themes of our time: the growing tendency to solve political problems with technology – a trend encouraged by Silicon Valley – and the growing focus on identity politics. A moment at which these two developments were most visible was in 2015 when emoji suddenly took on a skin colour. This contribution to Sign of the Times investigates how we reached this point based on a genealogy of the Person With Ball  emoji.
emoji.
Like all emoji, began as a proposal to be included in the Unicode Standard. This standard is managed by the Unicode Consortium, a non-profit organisation devoted to developing software internationalisation standards1.The Consortium’s work relates to the use and representation of all signs and fonts in digital media, whether on computers, mobile phones or websites. In this capacity, the Unicode Consortium is responsible for an important underlying infrastructure in digital communications. The Unicode Standard published by the organisation aims to standardise the encoding of signs so that it is possible to render different languages and symbols in the same way no matter what the platform. The idea behind Unicode dates back to the end of the 1980s, when it became clear that international data transfer via email and the emerging internet led to illegible documents. This encoding is, in fact, the translation between binary instructions for the computer and a legible document for the user. So, a document encoded in the Japanese Shift JIS coding will lead to an illegible document in the American ASCII coding: both coding systems allocate different signs to the same binary code. The envisaged solution to this problem was a single universal coding. The Unicode Standard a vast table in which, to date, 128,000 different characters are linked to unique binary numbers known as code points.
For this reason, Unicode’s priority was and remains the inclusion of as many existing text codes as possible within this table, thus confirming the status of existing standards. In this sense, the system is normative. The proposal to include was part of a larger proposal to incorporate a variety of symbols already used by ARIB, Japan’s media standardisation organisation2. The icon was part of a set of cartographic symbols and originally bore the name ![]() ‘track and field / gymnasium’3. Upon its incorporation within Unicode, it was given the number ‘U+26F9’ and a new name: ‘Person With Ball’. Strictly speaking, Unicode is concerned simply with linking the idea of a symbol with a code point and not with the ultimate form of that symbol, the glyph, which is designed by typographers.4 However, Unicode always provides a description and a suggested representation. Although these should not be seen as the official form or meaning, in practice this is indeed the case. The effect of this is that Unicode publications have become authoritative for the ultimate form of a symbol. Incorporating the ARIB symbol with a new description resulted in a small but influential shift in the symbol’s meaning: from a symbol on maps representing an object to a symbol representing a person with a ball. That this occurred was actually not such a big issue given that from the 1990s the Unicode Consortium always carried out its work in the background, in the relative obscurity afforded by these technological and bureaucratic tasks. One year after the introduction of , this would begin to change.
‘track and field / gymnasium’3. Upon its incorporation within Unicode, it was given the number ‘U+26F9’ and a new name: ‘Person With Ball’. Strictly speaking, Unicode is concerned simply with linking the idea of a symbol with a code point and not with the ultimate form of that symbol, the glyph, which is designed by typographers.4 However, Unicode always provides a description and a suggested representation. Although these should not be seen as the official form or meaning, in practice this is indeed the case. The effect of this is that Unicode publications have become authoritative for the ultimate form of a symbol. Incorporating the ARIB symbol with a new description resulted in a small but influential shift in the symbol’s meaning: from a symbol on maps representing an object to a symbol representing a person with a ball. That this occurred was actually not such a big issue given that from the 1990s the Unicode Consortium always carried out its work in the background, in the relative obscurity afforded by these technological and bureaucratic tasks. One year after the introduction of , this would begin to change.
Around 2010, Unicode standardised a new series of symbols that were commonly used on mobile phones in Japan: emoji. This decision stemmed from the same idea of incorporating existing international text codes in the table. In order to avoid duplication, Unicode looked at the sort of symbols that were being used by Japanese telecoms companies and whether comparable symbols were already in the Unicode table and could be ‘reused’. From a technical standpoint, emoji became a ‘status’ accorded to a series of newly encoded symbols and to existing symbols. For example, ❤ had been part of the Unicode table since 1995 but was promoted to emoji status in 20105. One of the characteristics of emoji status is that a symbol has two modes of rendering: the normal, monochrome ‘text rendering’ and a colourful emoji rendering. It is with this colourful rendering that Apple succeeded in popularising emoji. The Apple font Apple Color Emoji was developed following the introduction of the iPhone in Japan. Once incorporated in the iPhone keyboard, the concept was introduced to a worldwide public. With the popularity of emoji, the Unicode Consortium’s work became more visible. The increased attention was positively received, but within the Consortium emoji were seen merely as a subsidiary issue in relation to the ‘real’ text coding work.
Simultaneously, the application of emoji continued to grow. Apple’s font became more influential because it was used not only on the iPhone but also within apps such as WhatsApp. Because the availability of detailed and attractive emoji fonts became an increasingly important sales argument for handsets and apps, many manufacturers began to compete with Apple by designing emoji in a similar fashion: using colour and a high level of detail. Within a diversity of rendering styles – for a period Google’s Android used non-humanoid Barbapappa-style figures – Apple’s ‘realistic, ‘high-resolution’ style dominated.

If you had to describe the Apple Color Emoji rendering of , you would probably arrive at something like ‘running girl with basketball’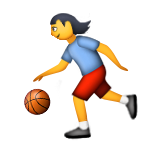 . It should be clear that with the increased resolution and detail, the range of interpretations of such symbols becomes limited and some possible meanings are excluded entirely. In the discourse in the United States informed by racial tensions, this Apple Color Emoji was eventually seen as ‘white’. Not least because, with its introduction of emoji representing LGBT couples, Apple had connected emoji to notions of representation and personal identity: issues intended to show the company in a modern and progressive light. Media outrage ensued about Apple’s ‘colour-blindness’, even though progressive identity politics was one of the pillars of the company’s communication. The repeated complaints that Apple received about its lack of emoji that represented different ethnicities was bad PR, and these complaints were passed on to Unicode. Apple’s argument was that it merely implemented Unicode’s standards (without admitting that Apple employees had helped to design the standard as part of Unicode). Whereas Unicode could normally take its time to deliberate new standards, there was now pressure to find a quick technical solution for what had become Unicode’s emoji ‘diversity problem’. Unicode quickly updated the standard with a new type of emoji that could be used to modify existing ‘humanoid’ emoji and to give them one of five skin colours. Consistent with the Consortium’s history of using existing standards, it opted to employ the Fitzpatrick scale, a six-grade scale that expresses skin’s sensitivity to UV rays. Unicode conveniently perceived the scale as neutral (because it was medical!), ignoring the fact that ‘scientific’ scales for skin colour are part of an implicitly colonial tradition. As a result, this solution intended to accommodate a post-colonial critique naturally missed its mark. To make matters worse, in the proposed Unicode standard the two ‘white’ grades in the scale were lumped together so that the current implementation comprises a single light colour and four increasingly dark colours6. The protagonist of our genealogy, , became one of the ‘humanoid’ emoji with a variable skin colour.
. It should be clear that with the increased resolution and detail, the range of interpretations of such symbols becomes limited and some possible meanings are excluded entirely. In the discourse in the United States informed by racial tensions, this Apple Color Emoji was eventually seen as ‘white’. Not least because, with its introduction of emoji representing LGBT couples, Apple had connected emoji to notions of representation and personal identity: issues intended to show the company in a modern and progressive light. Media outrage ensued about Apple’s ‘colour-blindness’, even though progressive identity politics was one of the pillars of the company’s communication. The repeated complaints that Apple received about its lack of emoji that represented different ethnicities was bad PR, and these complaints were passed on to Unicode. Apple’s argument was that it merely implemented Unicode’s standards (without admitting that Apple employees had helped to design the standard as part of Unicode). Whereas Unicode could normally take its time to deliberate new standards, there was now pressure to find a quick technical solution for what had become Unicode’s emoji ‘diversity problem’. Unicode quickly updated the standard with a new type of emoji that could be used to modify existing ‘humanoid’ emoji and to give them one of five skin colours. Consistent with the Consortium’s history of using existing standards, it opted to employ the Fitzpatrick scale, a six-grade scale that expresses skin’s sensitivity to UV rays. Unicode conveniently perceived the scale as neutral (because it was medical!), ignoring the fact that ‘scientific’ scales for skin colour are part of an implicitly colonial tradition. As a result, this solution intended to accommodate a post-colonial critique naturally missed its mark. To make matters worse, in the proposed Unicode standard the two ‘white’ grades in the scale were lumped together so that the current implementation comprises a single light colour and four increasingly dark colours6. The protagonist of our genealogy, , became one of the ‘humanoid’ emoji with a variable skin colour.
It should be clear that with this step, the link between emoji and identity politics became anchored and Pandora’s box was opened. Not only is there no end to the number of ethnic groups that need to be represented in the Unicode table, but the side effects are also considerable. For example, if you use the Instagram search engine to search for tags, you get different results for Fitzpatrick-1-2  and Fitzpatrick-6
and Fitzpatrick-6  , so that the content of the website is split, or indeed segregated, along racial lines7. That this is an unsolvable problem stems from the inherent contradiction of what Unicode is attempting to do. It is an organisation that aims to standardise syntactic linguistic elements – the smallest building blocks of a language or script. The problem that the Consortium has come up against is that it is now attempting to standardise at a semantic level, i.e. at the level of meaning, while meaning is so dependent upon context and, as shows us, changes over time8. Simpler, lower-resolution icons lend themselves to broader interpretation. The commercially driven tendency to design ever-more detailed emoji increasingly limits the possibilities for interpretation, with the result that people do not recognise themselves in them. It is, of course, questionable to what extent you should want to recognise yourself in a designed icon driven entirely by commercial concerns, especially now that emoji are becoming increasingly realistic and less playful. In any case, the transformation of has not yet come to an end: at the time of writing this text,
, so that the content of the website is split, or indeed segregated, along racial lines7. That this is an unsolvable problem stems from the inherent contradiction of what Unicode is attempting to do. It is an organisation that aims to standardise syntactic linguistic elements – the smallest building blocks of a language or script. The problem that the Consortium has come up against is that it is now attempting to standardise at a semantic level, i.e. at the level of meaning, while meaning is so dependent upon context and, as shows us, changes over time8. Simpler, lower-resolution icons lend themselves to broader interpretation. The commercially driven tendency to design ever-more detailed emoji increasingly limits the possibilities for interpretation, with the result that people do not recognise themselves in them. It is, of course, questionable to what extent you should want to recognise yourself in a designed icon driven entirely by commercial concerns, especially now that emoji are becoming increasingly realistic and less playful. In any case, the transformation of has not yet come to an end: at the time of writing this text,  is called ‘Person Bouncing Ball’ and can now be male, female or ‘neutral’, in which the neutral rendering is identical to the male version. In short, this story is far from over.
is called ‘Person Bouncing Ball’ and can now be male, female or ‘neutral’, in which the neutral rendering is identical to the male version. In short, this story is far from over.

This contribution is based on the essay ‘Modifiying the Universal’, written together with Femke Snelting and Peggy Pierot and published in the collection of essays Executing Practices: http://www.data-browser.net/06/
-
Although the Consortium strives for an open management model in which various interested parties are represented in developing the standard, not all parties have voting rights (at a cost of $18,000 per year to approve or reject proposals), see http://unicode.org/Consortium/levels.html. Seven of the nine interested parties who (can) pay for voting rights are American technology firms: Adobe, Apple, Google, IBM, Microsoft, Oracle and Yahoo, see http://www.unicode.org/consortium/members.html. ↩︎
-
Association of Radio Industries and Businesses. The proposal to include the ARIB symbols in Unicode: http://www.unicode.org/L2/L2007/07391-n3341.pdf ↩︎
-
The original ARIB coding: http://www.arib.or.jp/english/html/overview/doc/6-STD-B24v5_1-1p3-E1.pdf ↩︎
-
Unicode standards are thus based on the fact that, for example, the binary number ‘97’ is always linked to the idea of a lower-case ‘a’ and not whether it appears as ‘a’, ‘a’ or ‘a’. ↩︎
-
Another question is why not all Unicode pictograms, such as ☭, have not been granted emoji status. ↩︎
-
In April 2016, in the context of a workshop (http://softwarestudies.projects.cavi.au.dk/index.php/*.exe_(ver0.2), we wrote a commentary on this and sent it to Unicode, see. The commentary can be read here: http://possiblebodies.constantvzw.org/feedback.html ↩︎
-
http://rhizome.org/editorial/2015/dec/08/uif618-your-ascii-goodbye/ ↩︎
-
This issue is also the subject of Unicode Public Review Issue 294: Not a High Five, the work that I have made together with Dennis de Bel for Sign of the Times. We have “fixed” emoji could change in form or meaning in order to be legible to Western eyes, by making metal molds of them that can be used to make reproductions. ↩︎