Creating portable digital libraries by embedding metadata
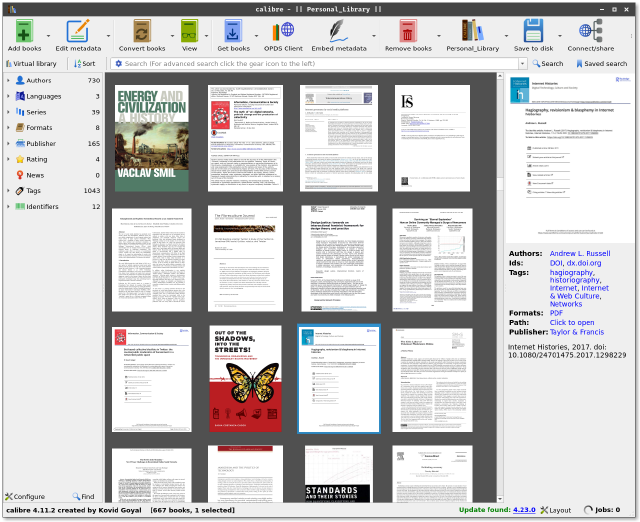
Tools like Calibre make it possible to organize digital publications into meaningful collections by adding a wealth of metadata to files. This makes it possible to organize and search publications according to theme, publisher, authors, year and more. There is also a ‘description’ field which allow for comments of different kinds, such as an abstract of the publication, or personal notes on its (ir)relevance. A well-tended collection which has been thoughtfully annotated can become a valuable research tool for individual or collective researchers.
The big downside however is that the annotations exist separately from the files in question. This means that if the document in question is shared, the rich annotations are lost. This is because by default Calibre saves all the meta-data in a separate file. It is however possible to embed metadata in digital publications, doing so can help turn a folder of PDFs into a portable library. This article will show how this can be done and discuss the benefits and potential downsides.
How is metadata stored in digital publications?
In PDFs metadata is stored in so-called XMP headers. This is an XML-based scheme that which can hold different metadata namespaces. The metadata in PDFS can be queried with exiftool or pdfinfo
So let’s take a look at the embedded metadata in a downloaded copy of Entreprecariat by Silvio Lorusso. I use this as an example because it is licensed CC-By-NC.
:::console
$ exiftool -a ~/Downloads/Lorusso_Silvio_Entreprecariat_Everyone_Is_an_Entrepreneur_Nobody_Is_Safe_2019.pdf
Which returns the following:
:::console
ExifTool Version Number : 11.16
File Name : Lorusso_Silvio_Entreprecariat_Everyone_Is_an_Entrepreneur_Nobody_Is_Safe_2019.pdf
Directory : /home/r/Downloads
File Size : 7.1 MB
File Modification Date/Time : 2020:09:14 12:11:15+02:00
File Access Date/Time : 2020:09:14 12:11:15+02:00
File Inode Change Date/Time : 2020:09:14 12:11:15+02:00
File Permissions : rw-r--r--
File Type : PDF
File Type Extension : pdf
MIME Type : application/pdf
PDF Version : 1.3
Linearized : No
XMP Toolkit : XMP Core 5.4.0
Creator Tool : Adobe InDesign CC (Macintosh)
Metadata Date : 2019:09:30 14:07:09+02:00
Create Date : 2019:09:30 14:06:54+02:00
Modify Date : 2019:09:30 14:07:09+02:00
Format : application/pdf
Original Document ID : xmp.did:77eb9a89-ab0d-4669-a071-891dd3c13e49
History Software Agent : Adobe InDesign CC (Macintosh)
History Parameters : from application/x-indesign to application/pdf
History Changed : /
History When : 2019:09:30 14:06:54+02:00
History Action : converted
Instance ID : uuid:d696f48c-7cbe-3b46-a3d2-48b7904b4eb4
Document ID : xmp.id:158e5a30-813c-4a76-9772-2ada50141a11
Derived From Rendition Class : default
Derived From Document ID : xmp.did:77eb9a89-ab0d-4669-a071-891dd3c13e49
Derived From Instance ID : xmp.iid:872edb25-4a31-4dbf-8907-edc9701bb1f6
Derived From Original Document ID: xmp.did:77eb9a89-ab0d-4669-a071-891dd3c13e49
Rendition Class : proof:pdf
Trapped : False
Producer : Adobe PDF Library 11.0
Page Count : 264
PDF Version : 1.4
Producer : Mac OS X 10.9.5 Quartz PDFContext
Creator : Adobe InDesign CC (Macintosh)
Create Date : 2019:09:30 12:07:29Z
Modify Date : 2019:09:30 12:07:29Z
To get the raw XMP metadatafields you can use the tool pdfinfo.
:::console
$ pdfinfo -meta ~/Downloads/Lorusso_Silvio_Entreprecariat_Everyone_Is_an_Entrepreneur_Nobody_Is_Safe_2019.pdf
<x:xmpmeta xmlns:x="adobe:ns:meta/" x:xmptk="XMP Core 5.4.0">
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about=""
xmlns:xmp="http://ns.adobe.com/xap/1.0/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:xmpMM="http://ns.adobe.com/xap/1.0/mm/"
xmlns:stEvt="http://ns.adobe.com/xap/1.0/sType/ResourceEvent#"
xmlns:stRef="http://ns.adobe.com/xap/1.0/sType/ResourceRef#"
xmlns:pdf="http://ns.adobe.com/pdf/1.3/">
<xmp:CreatorTool>Adobe InDesign CC (Macintosh)</xmp:CreatorTool>
<xmp:MetadataDate>2019-09-30T14:07:09+02:00</xmp:MetadataDate>
<xmp:CreateDate>2019-09-30T14:06:54+02:00</xmp:CreateDate>
<xmp:ModifyDate>2019-09-30T14:07:09+02:00</xmp:ModifyDate>
<dc:format>application/pdf</dc:format>
<xmpMM:OriginalDocumentID>xmp.did:77eb9a89-ab0d-4669-a071-891dd3c13e49</xmpMM:OriginalDocumentID>
<xmpMM:History>
<rdf:Seq>
<rdf:li rdf:parseType="Resource">
<stEvt:softwareAgent>Adobe InDesign CC (Macintosh)</stEvt:softwareAgent>
<stEvt:parameters>from application/x-indesign to application/pdf</stEvt:parameters>
<stEvt:changed>/</stEvt:changed>
<stEvt:when>2019-09-30T14:06:54+02:00</stEvt:when>
<stEvt:action>converted</stEvt:action>
</rdf:li>
</rdf:Seq>
</xmpMM:History>
<xmpMM:InstanceID>uuid:d696f48c-7cbe-3b46-a3d2-48b7904b4eb4</xmpMM:InstanceID>
<xmpMM:DocumentID>xmp.id:158e5a30-813c-4a76-9772-2ada50141a11</xmpMM:DocumentID>
<xmpMM:DerivedFrom rdf:parseType="Resource">
<stRef:renditionClass>default</stRef:renditionClass>
<stRef:documentID>xmp.did:77eb9a89-ab0d-4669-a071-891dd3c13e49</stRef:documentID>
<stRef:instanceID>xmp.iid:872edb25-4a31-4dbf-8907-edc9701bb1f6</stRef:instanceID>
<stRef:originalDocumentID>xmp.did:77eb9a89-ab0d-4669-a071-891dd3c13e49</stRef:originalDocumentID>
</xmpMM:DerivedFrom>
<xmpMM:RenditionClass>proof:pdf</xmpMM:RenditionClass>
<pdf:Trapped>False</pdf:Trapped>
<pdf:Producer>Adobe PDF Library 11.0</pdf:Producer>
</rdf:Description>
</rdf:RDF>
</x:xmpmeta>
So while this pdf contains plenty of metadata, it is mostly technical in nature. It contains the software the publication was made with, when it was made, how big it is etc. But it tells us very little about the topic of the book. This kind of semantic metadata is what I want to address here though.
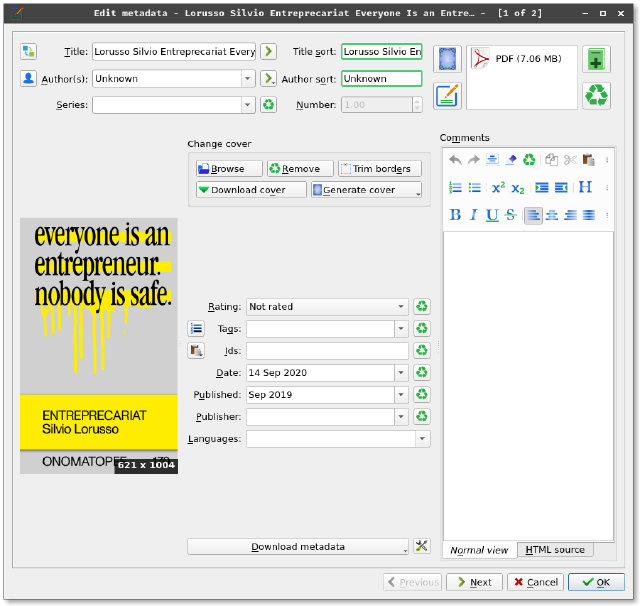
As a consequence of the lack of metadata, importing this publication in Calibre or other similar software will make it appear with empty metadata fields such as author and title.
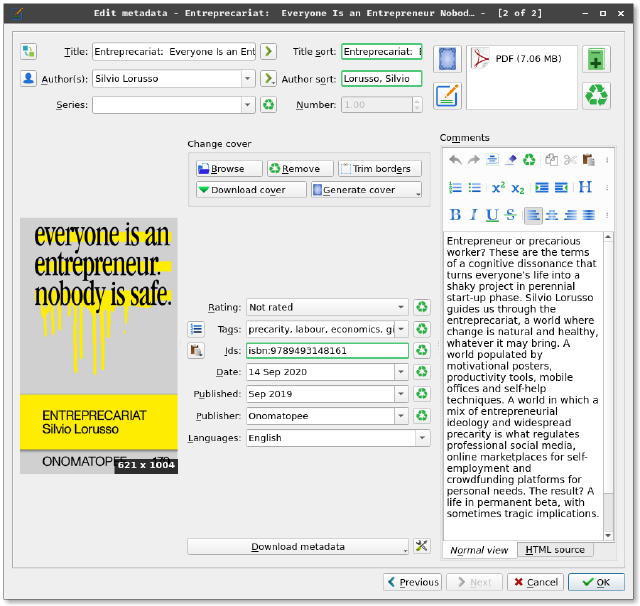
With a bit of work, though, metadata can be added (and refined over time!) so that the particular work can become part of a meaningful collection. However, attaching the metadata to the file itself would be valuable. So that another can be saved the labour of adding the most mundane tags but more importantly, to be able to share additional knowledge as you share the file.
How to embed metadata in files using Calibre
There is in fact an inbuilt function in Calibre which writes the metadata to the XMP fields of the file. It can be found (and added to the toolbar) by going to Preferences > Toolbars & Menus > The Main Toolbar. There you find two columns, on the left you will find an action called ‘Embed Metadata’, which can be added to the column on the right to be permantently accessible.
Having one or multiple publications selected and pressing that button will write the metadata to the XMP headers. There is no feedback on this but it can be verified by running exiftool for a second time:
:::console
$ exiftool -a Entreprecariat_Everyone-Is-an-Entrepreneur_Silvio-Lorusso.pdf
This now shows us that the metadata is embedded in the document. n.b. I have omitted most lines that contained technical metadata for brevity:
:::console
File Type Extension : pdf
MIME Type : application/pdf
PDF Version : 1.4
Linearized : No
Author : Silvio Lorusso
Create Date : 2019:09:30 12:07:29Z
Creator : Adobe InDesign CC (Macintosh)
Keywords : precarity, labour, economics, gig work, entrepreneurialism, ideology, productivity, neo-liberalism, design theory
Modify Date : 2020:09:14 15:44:43+02:00
Producer : Mac OS X 10.9.5 Quartz PDFContext
Title : Entreprecariat: Everyone Is an Entrepreneur Nobody Is Safe
Title : Entreprecariat: Everyone Is an Entrepreneur Nobody Is Safe
Description : <div>.<p>Entrepreneur or precarious worker? These are the terms of a cognitive dissonance that turns everyone’s life into a shaky project in perennial start-up phase. Silvio Lorusso guides us through the entreprecariat, a world where change is natural and healthy, whatever it may bring. A world populated by motivational posters, productivity tools, mobile offices and self-help techniques. A world in which a mix of entrepreneurial ideology and widespread precarity is what regulates professional social media, online marketplaces for self-employment and crowdfunding platforms for personal needs. The result? A life in permanent beta, with sometimes tragic implications.</p>.<p> </p>.<p>With a foreword by Geert Lovink and an afterword by Raffaele Alberto Ventura.</p></div>
Creator : Silvio Lorusso
Publisher : Onomatopee
Subject : precarity, labour, economics, gig work, entrepreneurialism, ideology, productivity, neo-liberalism, design theory
Date : 2019:09:30 14:06:54+02:00
Language : en
Format : application/pdf
Identifier Scheme : isbn
Identifier : 9789493148161
Metadata Date : 2020:09:14 15:44:43.150519+02:00
Creator Tool : Adobe InDesign CC (Macintosh)
Create Date : 2019:09:30 14:06:54+02:00
Modify Date : 2019:09:30 14:07:09+02:00
Timestamp : 2020:09:14 12:19:53+02:00
Author link map : {"Silvio Lorusso": ""}
Title sort : Entreprecariat: Everyone Is an Entrepreneur Nobody Is Safe
Author sort : Lorusso, Silvio
Trapped : False
Likewise the PDF metadata generated by pdfinfo -meta can be found here).
Not only can this be done from the Calibre graphical interface, embedding metadata can also be done from the Calibre command line utilities:
:::console
$ calibredb --library-path=/path/to/library embed_metadata all
This can be particularly helpful when connecting using a Calibre library with Calibre-web for shared collections. Note that Calibre-web currently does not import embedded metadata. At least not until this pull request gets merged.
Conclusions
This post demonstrated how to embed metadata in PDFs to create portable libraries. By this I refer to the fact that the metadata (ordering, categorization, contextualization) which makes up such a big part of what makes a library, can travel with the documents as they are shared. There was no discussion of .epub files though, partly because these tend to have embedded metadata much more often, since it is better standardized. The benefit to embedding metadata is twofold: Particularly when it comes to the objective fields such author and title, having embedded metadata can save a lot of time. Embedding subjective metadata, such as tags, categorization, comments makes, it possible to share additional knowledge about the document. There is also the biggest downside however, metadata can be highly subjective and personal. Therefore it could be of little value to someone, or even worse could leak personal information about the librarian. However, being able to circulate documents to particular individuals with those additional insights attached is a huge boon when it comes to building shared knowledge bases.